杜老师找到了一款工具,可以通过自己音色训练模型,然后通过文字转换语音,之前关于 DDoS 文章中的语音就是通过该工具生成。已经整理成一键包,感兴趣的小伙伴可以尝试下。
食用步骤
先解压压缩包,这里需要注意的是,路径中尽量不要出现中文的字符。找到并打开启动webui:
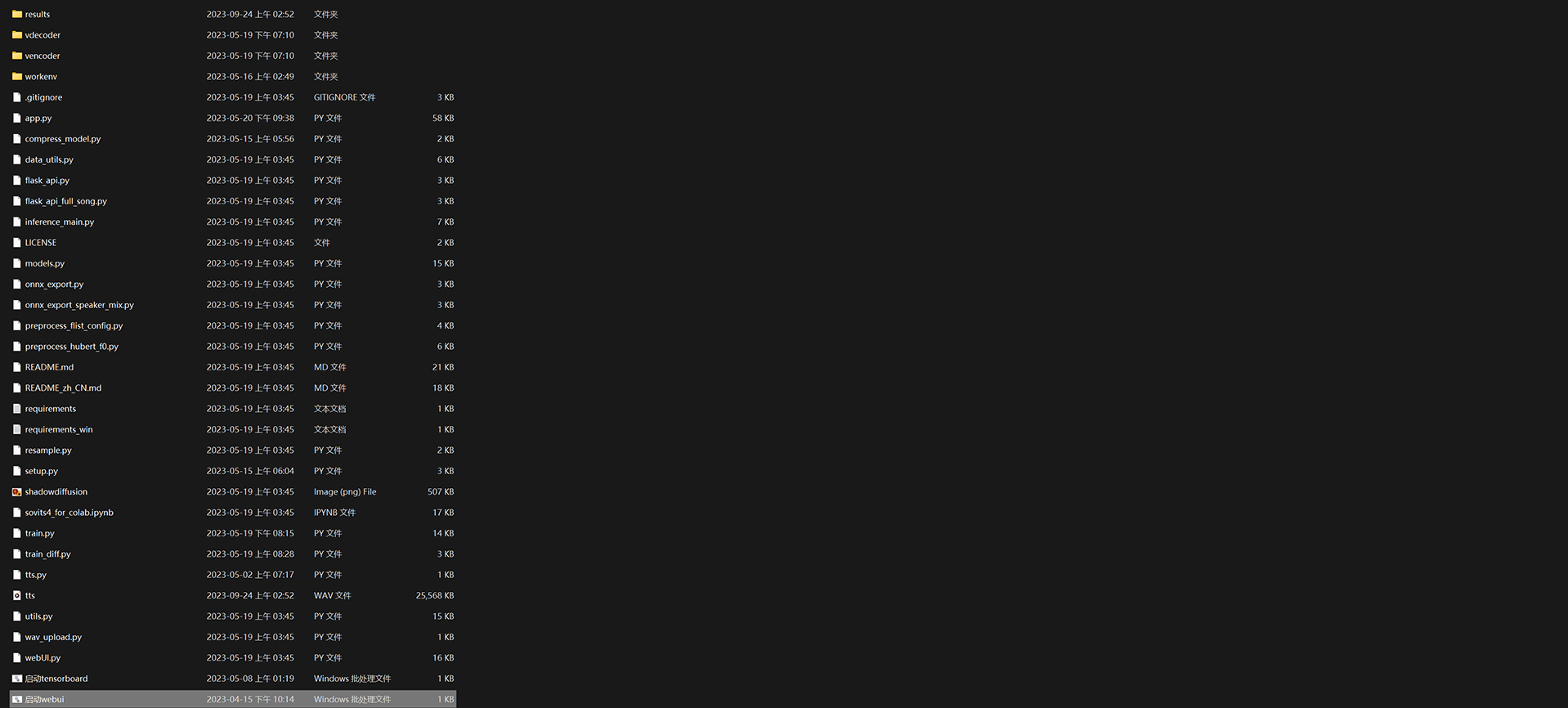
会弹出 CMD 窗口,根据脚本自动安装所需要的运行环境,带安装完成后,会自动弹出浏览器打开工具页面「如果没有自动打开,可根据窗口 URL 提示手动打开」
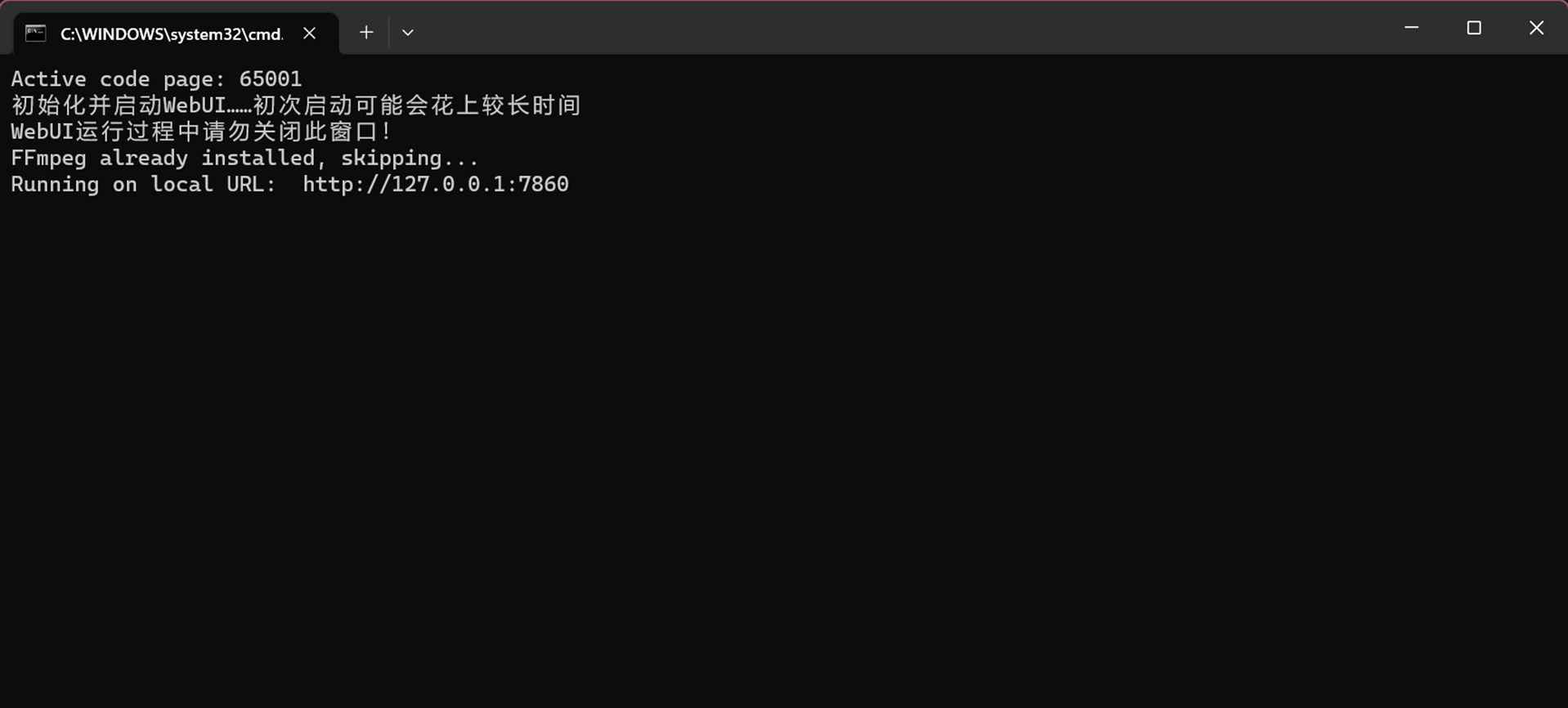
在训练前,先录制一段不低于十分钟的声音「时长越久越好,音质越高越好,背景音越纯净越好」对声音文件做切片:
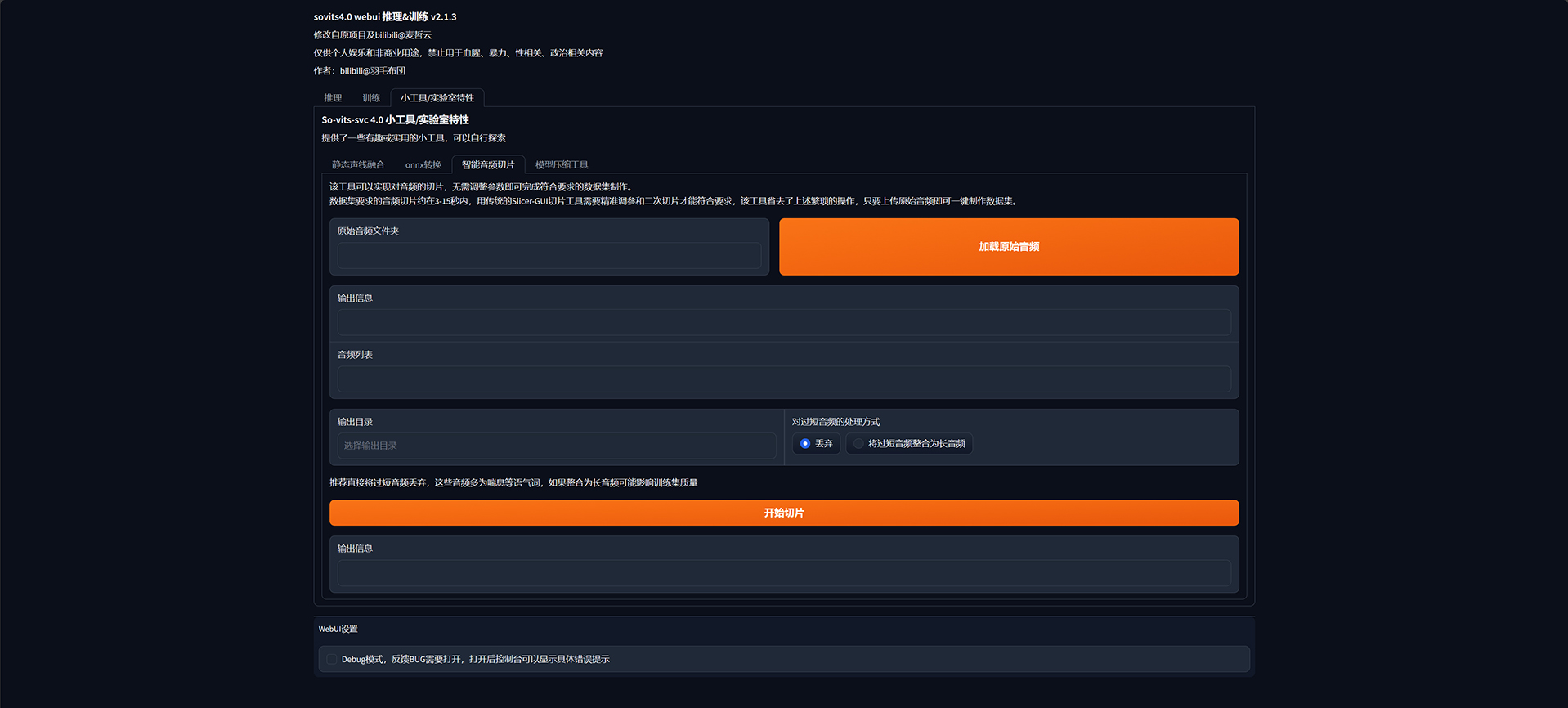
将切割后的 WAV 文件放入 dataset_raw/OUT 目录中:
切换到训练项,先点击识别数据集,然后点数据预处理:
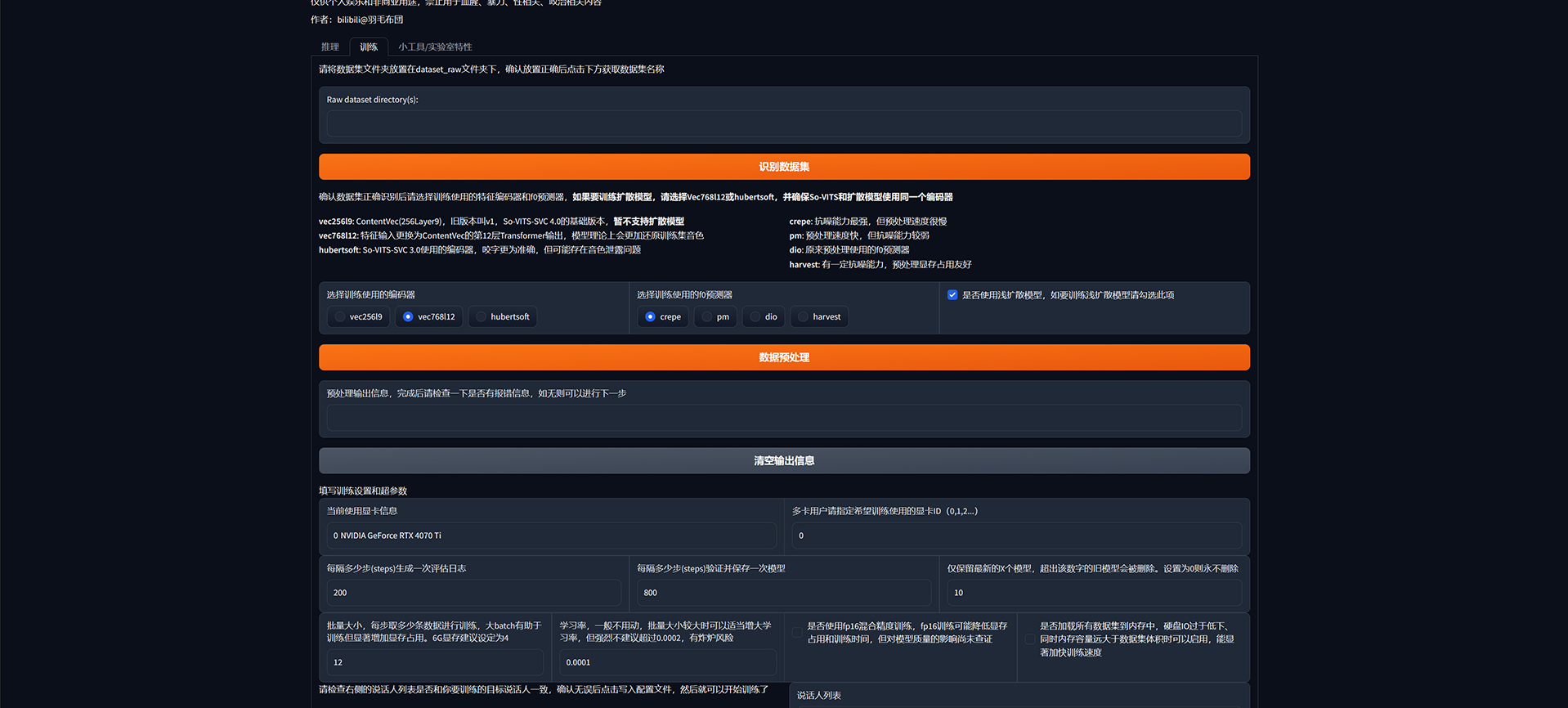
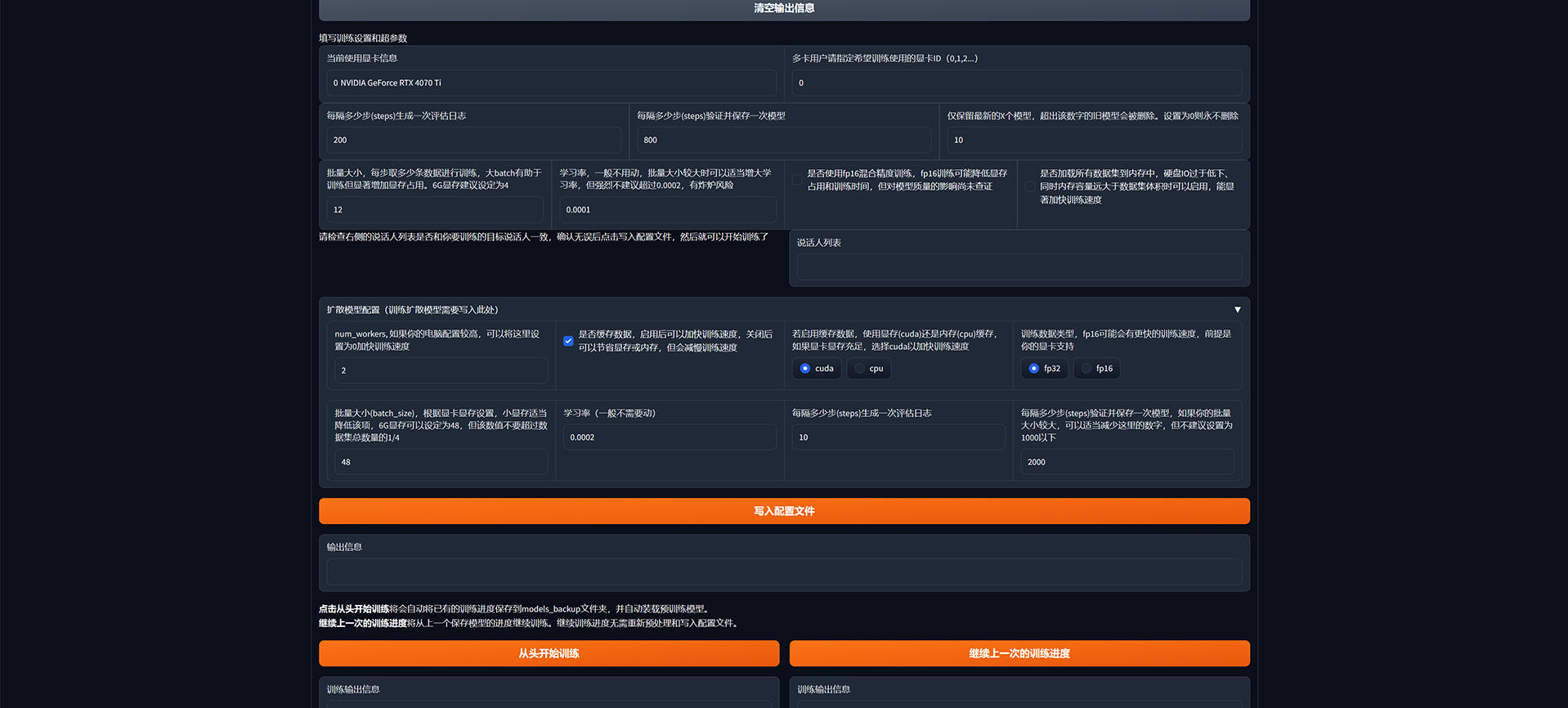
待预处理完成之后,点击写入配置文件,然后就可以开始训练了:
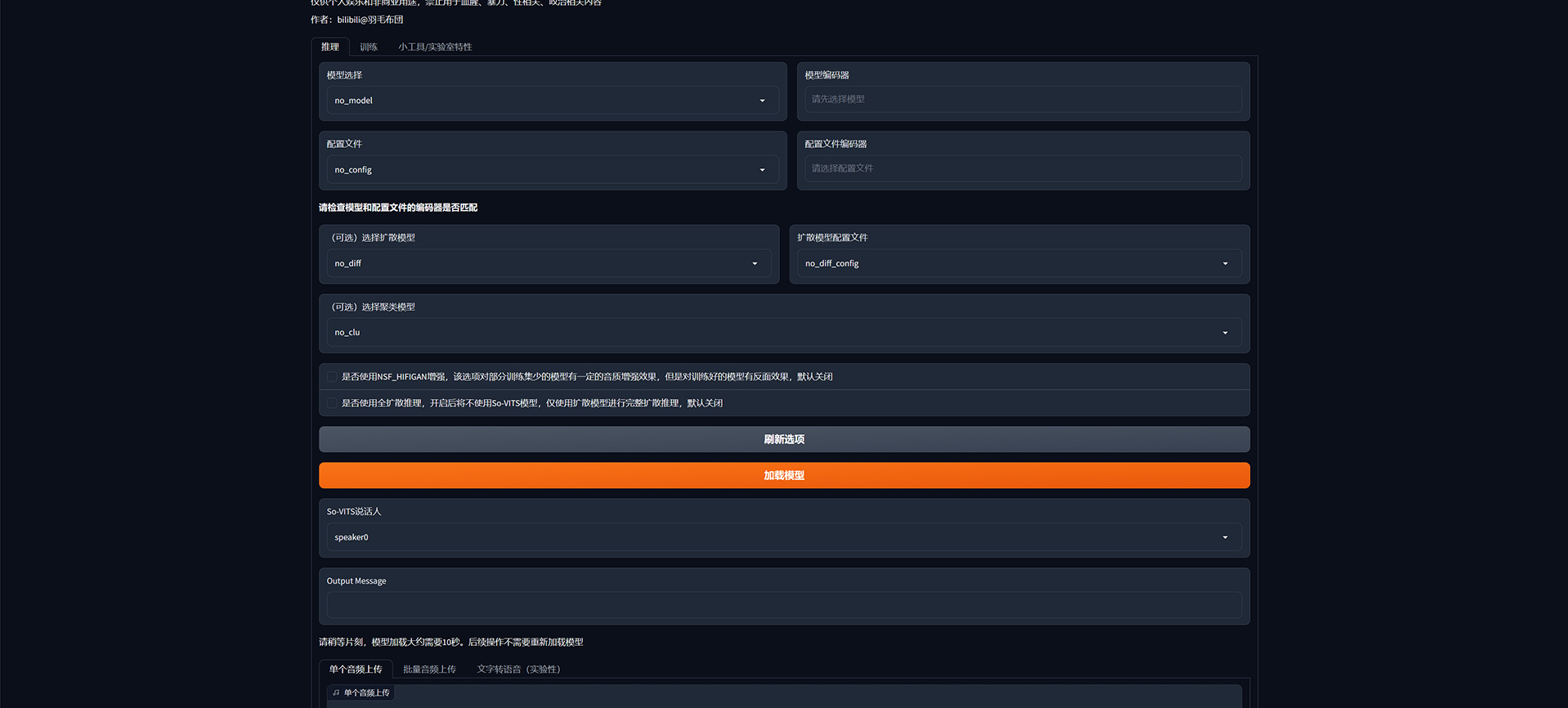
如果需要使用模型,则切换推理项:
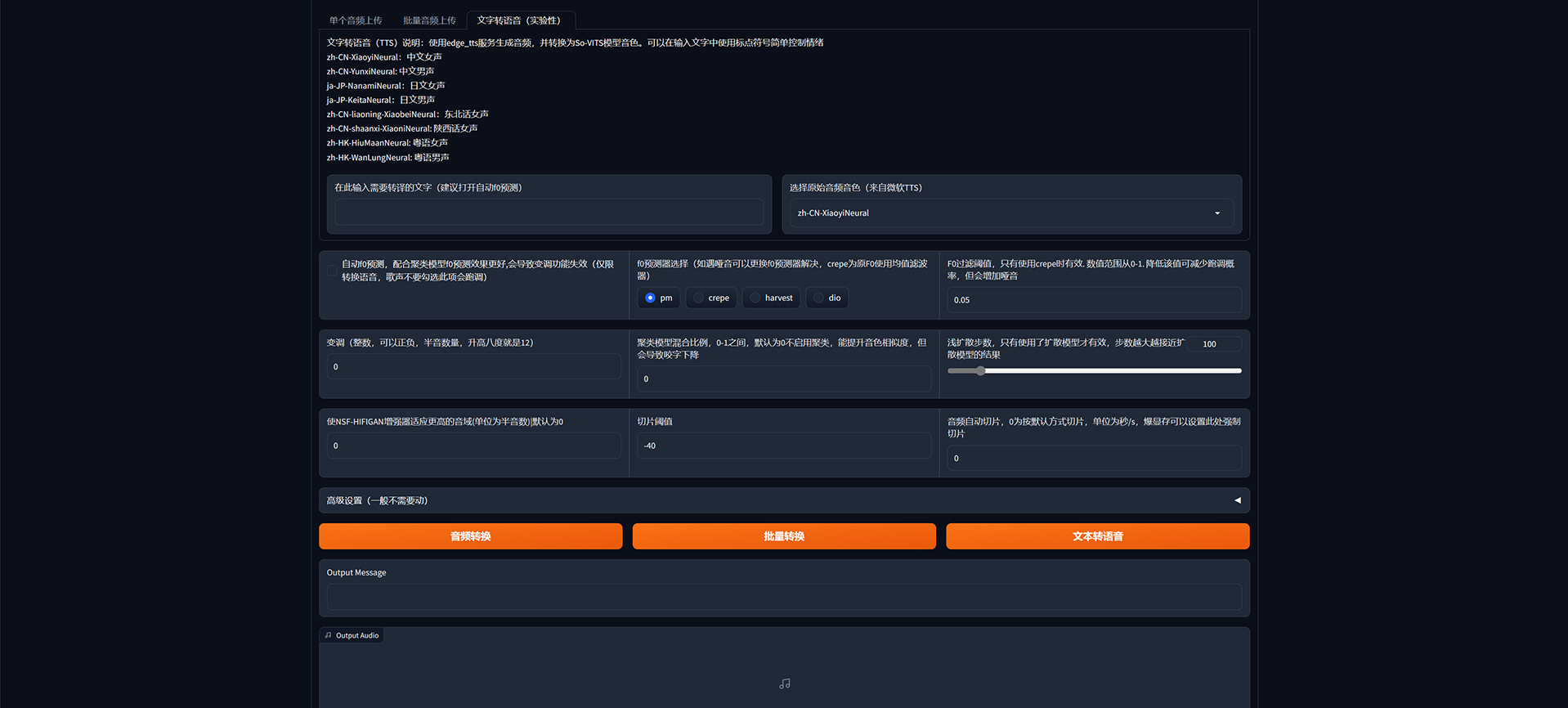
最后切换到文字转语音,输入编辑好的文字,建议勾选中自动f0预测,点击下方的文本转语音即可:
下载地址
下载地址:
下载地址